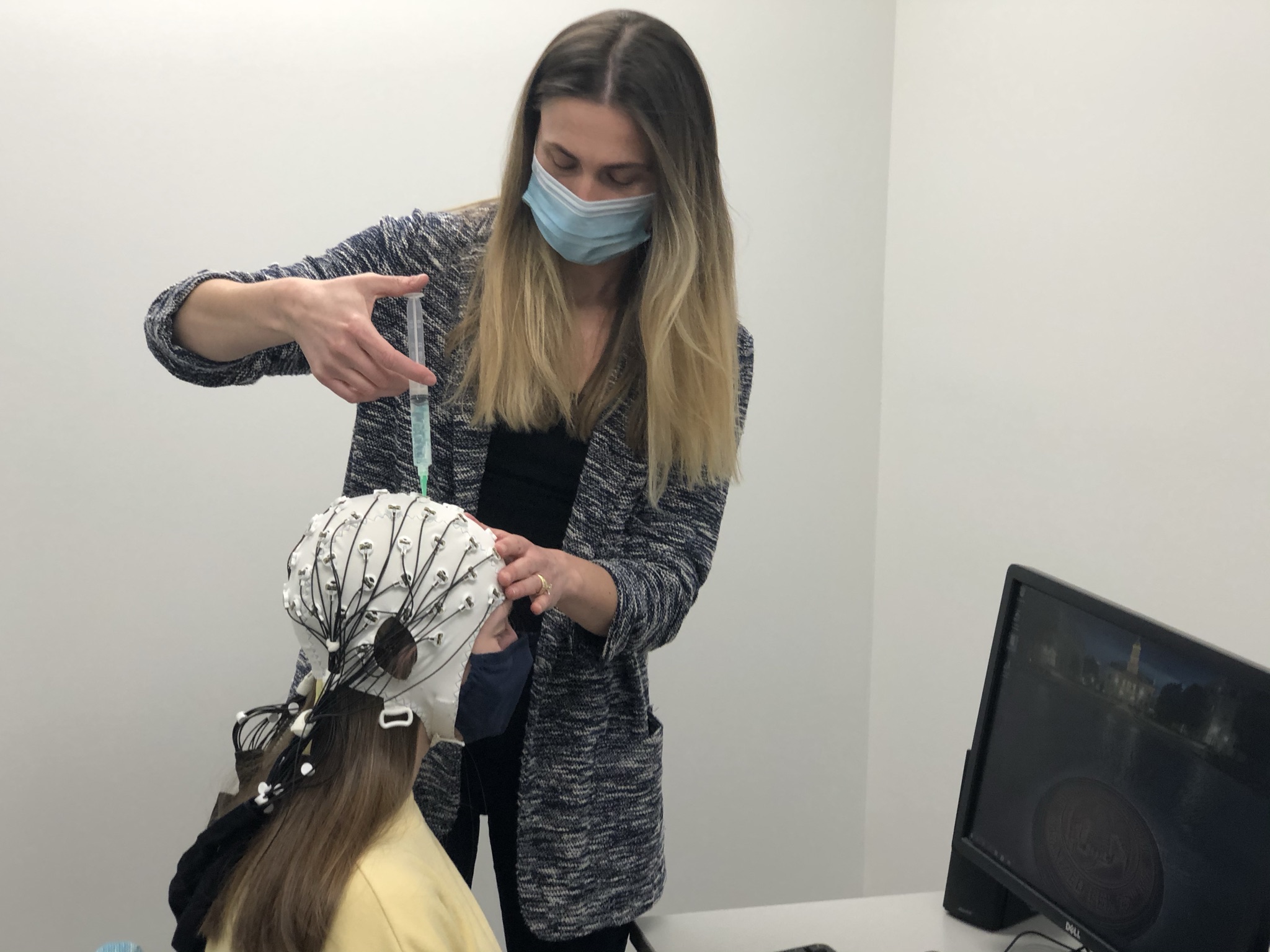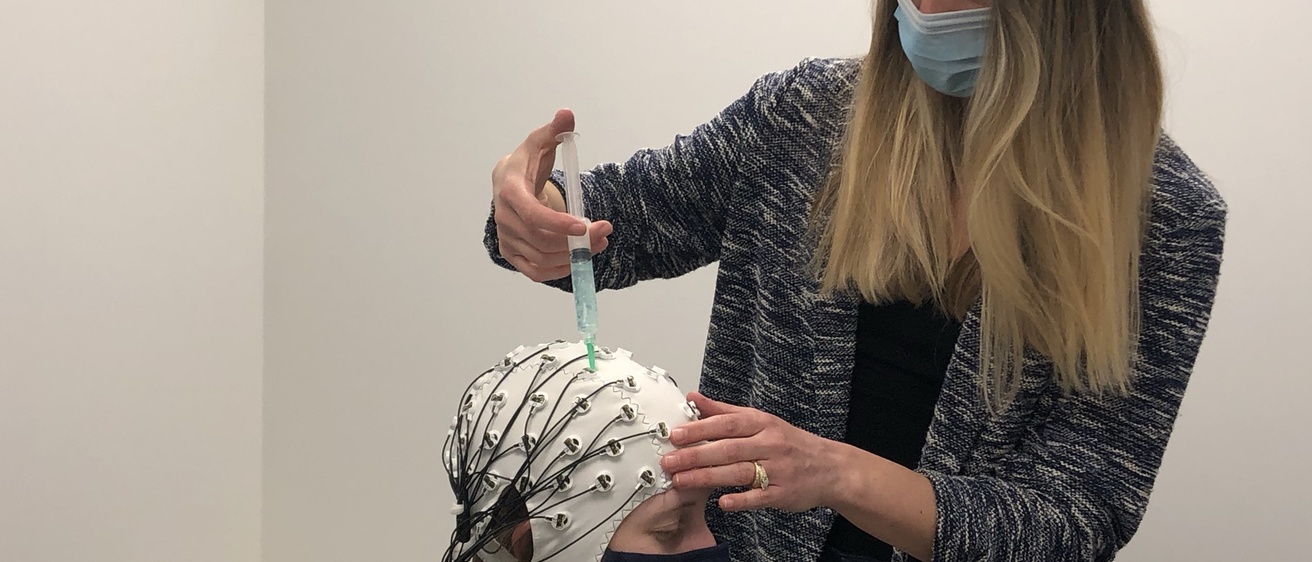
Our Goal
Our primary area of research is spoken and written language processing. We examine how listeners and readers recognize the words they hear and read, how the meanings of words are accessed, and how individuals predict upcoming words during incremental sentence processing. We examine these processes in children and adults, individuals with normal hearing and those who are hard of hearing, and in populations who speak more than one language. We use eye-tracking and Electroencephalography as tools of investigation, and we have helped to develop state-of-the-art statistical approaches to analyzing time series data. Our long-term goal is to development a theory of word recognition and language processing that not only explains how typical listeners who are monolingual adults process language, but is ecologically valid enough to extend to children, adverse listening conditions, and in populations who are multilingual.
Current Projects
Spoken and Written Word Recognition
Word recognition is a complex cognitive process that is fundamental to language and reading. For most individuals, word recognition occurs across two sensory modalities: auditory (spoken words) and visual (written words). Though each recognition system faces distinct sensory and cognitive challenges, both spoken and written word recognition involve competition mechanisms in which multiple lexical candidates compete for recognition. While there is a rich history of literature documenting these mechanisms in each modality, these two literatures have been largely disparate. In this line of research, we and offer avenues to characterizing the core mechanisms of each in a common set of computational principles.
Role of Inhibition and Sentence Processing
To comprehend spoken sentences efficiently, listeners predict upcoming words depending on the sentence context. However, listeners’ predictions are not always correct. For example, in a sentence like, On sunny days, Jake visits the park to walk his monkey, the word monkey is a plausible completion, but it is highly unexpected. It has been proposed that in order to integrate the unexpected word and comprehend the sentence, listeners must inhibit the predicted and highly active word “dog” (e.g., DeLong & Kutas, 2020). However, this assertion is largely speculative. The major aim of this research is to present empirical evidence that listeners inhibit activation for a predicted word when their prediction is violated. Further, we seek to understand whether local language specific or more globally inhibitory control mechanisms are responsible for this inhibition.
Bilingual Word Recognition
Children who speak and read in two languages are the norm around the world and in many US communities. However, there is a gap in understanding how language and literacy develops in bilingual and biliterate children. A fundamental component of language and literacy development is word recognition. Central to both spoken and written word recognition is competition: given a word (e.g., cap), multiple lexical candidates are activated (e.g., cap, cab, cat) and compete for recognition. The nature of lexical competition within and across languages in children is largely unaddressed. This is a crucial limitation as prominent theories of bilingual language and cognition rest on how these skills develop. This is of clinical significance because for monolingual children, the ability to manage competition is highly predictive of language and literacy outcomes and represents significant challenges for children with language disorders (McMurray et al., 2010). Because there are health disparities that perpetuate disproportionate educational achievement for many Spanish-English learners in the US, it is crucial that our theoretical models extend beyond single-language learners, to students who hear and read words in more than one language. The proposed research addresses this limitation in two aims. In Aim 1, we characterize competition for spoken and written words within and across languages in Spanish-English dual language learners during a developmental period characterized by variability in word-level reading skills (middle school). We developed a novel variant of an eye-tracking paradigm to measure both spoken and written word recognition. Individuals hear or see a word and click the corresponding picture from a display of four: the target (e.g., cap), an acoustically and visually similar competitor (e.g., cab) and unrelated items (e.g., net and mud). Eye-movements are time-locked to the dynamics of lexical competition. Given that there are more differences in speech sounds than in letters across languages (e.g., the speech sound /b/ differs in English and Spanish, yet the letter “b” is identical), we predict that for spoken words, competition will be greater within than across languages, whereas for written words, competition will be similar within and across languages. In Aim 2, we take an individual differences approach and examine how language and reading proficiency influence these competition dynamics. This aim will determine the sources of variability that promote proficient bilingual and biliterate children to achieve efficient word recognition. The current research has a broad-based appeal for theories of language processing because it will help characterize a core set of computational principles involved in spoken and written word recognition.
Language Outcomes and Mechanisms in adults with and without Developmental Language Disorder
The objective of this newly NIH-funded project is to characterize the long-term outcomes of Developmental Language Disorder in adulthood and to identify specific cognitive mechanisms mediating these outcomes. We utilize a large, pre-existing dataset and participant pool from one of the most comprehensive examinations of DLD to date: the Iowa Longitudinal Study. We leverage retrospective language measures from kindergarten through 10th grade and collect new outcome measures in adulthood to characterize the long-term outcomes of DLD. Further, we measure real-time language processing across language modality (comprehension, production) and level (word, sentence, discourse) using eye-tracking. The proposed work represents one of the largest and most comprehensive characterization of language abilities in adults with (and without) DLD to date.
Research